

生物类的小硕毕业后想从事生物信息学的工作,计算机基础0,想问生信入门需要具备啥能力,可具体推荐几本书,thanks.
生物类的小硕毕业后想从事生物信息学的工作,计算机基础0,想问生信入门需要具备啥能力,可具体推荐几本书,thanks.
 鸭肠一次吃几个-30串10元的鸭肠,为啥这么便宜?老板透露其中奥秘,你2023-04-11
鸭肠一次吃几个-30串10元的鸭肠,为啥这么便宜?老板透露其中奥秘,你2023-04-11 宝格丽bvlfari-路易威登秋冬女装生机盎然,宝格丽新款珠宝优雅别致2023-03-13
宝格丽bvlfari-路易威登秋冬女装生机盎然,宝格丽新款珠宝优雅别致2023-03-13 给大家科普下operaminiinstall,Operamini download2023-03-30
给大家科普下operaminiinstall,Operamini download2023-03-30 心率正常范围是多少-心跳频率的安全范围是多少?出现什么情况应及时就医?2023-05-22
心率正常范围是多少-心跳频率的安全范围是多少?出现什么情况应及时就医?2023-05-22 投资资产的公司-美帝最大资本航母,众多知名企业的金主,创始人资产却不足2023-03-18
投资资产的公司-美帝最大资本航母,众多知名企业的金主,创始人资产却不足2023-03-18 调查称在 1000 家受访企业中已有近 250 家让 ChatGPT 其代替员工工作,如何看待此现象?2023-03-01
调查称在 1000 家受访企业中已有近 250 家让 ChatGPT 其代替员工工作,如何看待此现象?2023-03-01 海尔冰箱售后电话-海尔冰箱24小时人工服务电话2023-04-26
海尔冰箱售后电话-海尔冰箱24小时人工服务电话2023-04-26 给大家科普下最大的鲸鱼是什么鲸-世界最大的鲸鱼是什么鲸2023-03-28
给大家科普下最大的鲸鱼是什么鲸-世界最大的鲸鱼是什么鲸2023-03-28 可以秀恩爱么-情侣在一起后要不要公开秀恩爱?2023-04-09
可以秀恩爱么-情侣在一起后要不要公开秀恩爱?2023-04-09 比翼鸟指什么生肖-山海经:在天愿作比翼鸟,在地愿为连理枝,比翼鸟的来历2023-08-09
比翼鸟指什么生肖-山海经:在天愿作比翼鸟,在地愿为连理枝,比翼鸟的来历2023-08-09 白果是什么-白果是什么东西2023-02-16
白果是什么-白果是什么东西2023-02-16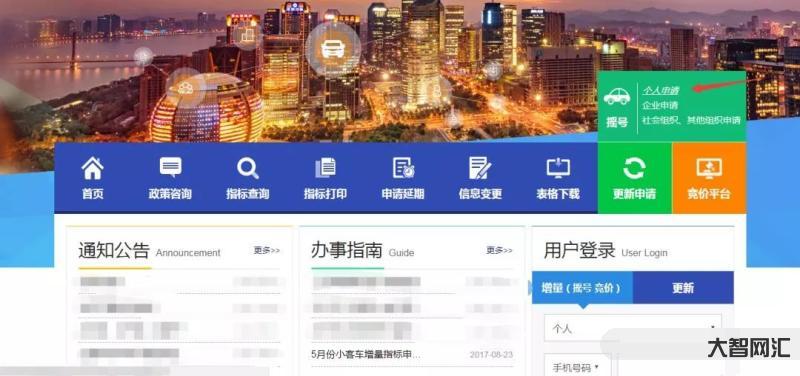 车牌指标如何摇-车牌号怎么摇号申请?2023-03-21
车牌指标如何摇-车牌号怎么摇号申请?2023-03-21 北京卖汽车最好的-北京奔驰营收1827亿元,净利270亿元!但北汽还能2023-03-30
北京卖汽车最好的-北京奔驰营收1827亿元,净利270亿元!但北汽还能2023-03-30 鹿茸蜡片怎么吃-鹿茸片炖汤的做法2023-03-06
鹿茸蜡片怎么吃-鹿茸片炖汤的做法2023-03-06 养肝护肝吃什么-吃什么养肝护肝2023-02-28
养肝护肝吃什么-吃什么养肝护肝2023-02-28







